汇聚海量数据,打造智慧出行新体验
3月6日 · 华为IT产品线副总裁 科技领域创作者
万物联接,自动驾驶的未来已来
汽车产业伴随着工业革命而生,从1.0时代机械化、2.0时代电气化、3.0时代机电一体化,每一次工业革命都带来了汽车产业的重大变革。工业4.0时代,汽车产业将迎来什么变化?
工业4.0时代,新技术和商业模式驱动传统汽车制造商向出行服务及产品综合供应商转型,汽车产业走向“四化(智能化、网联化、电动化、共享化)”成为各大车企的共识:

电动化:电动汽车无疑是新能源领域最被认可的方向。2025年,25%的乘用车将是新能源汽车。
自动驾驶:基于AI,实现自动驾驶感知、规划、决策、执行,2030年,10-15%的汽车完全自动驾驶。自动驾驶对可靠性安全性要求愈发严格,对计算能力及数据传输的需求日益旺盛。
网联化:云端和汽车的联系将更加紧密,2030年,100%的汽车将联网,通过车、路、网、人、环境交互,降低车辆感知成本。
共享化:定制化的驾乘体验使车辆成为社会化出行服务工具,也将改变车辆的所有权结构。2030年,在路上跑的汽车,32%将是共享的。
自动驾驶已成为当前最炙手可热的领域,不管是国内还是海外、传统车企还是新造车势力,都将之视为汽车产业的下一波机会。
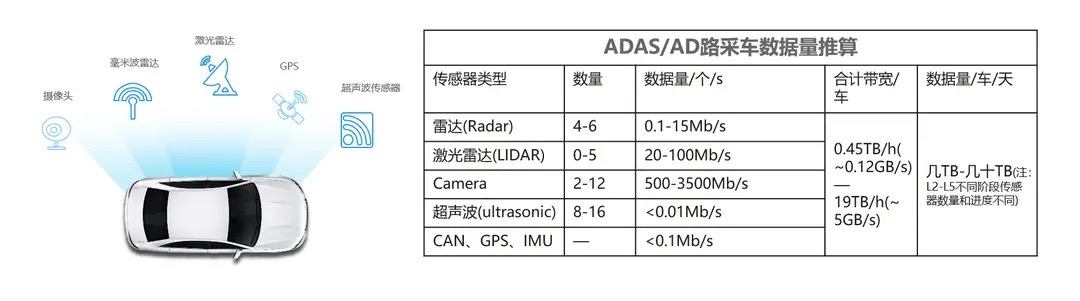
自动驾驶将带来海量的数据
按照SAE标准,自动驾驶分为五个等级:
0级:意味没有自动驾驶,司机负责控制一切。
1级:则意味着车辆进阶到了辅助驾驶阶段,在行驶中辅助系统能为司机分担不少任务(如 ACC)。
2级:意味着车辆进入半自动化状态,不过司机需要全程监控系统。同时,至少一个车载系统(如巡航控制和车道保持)实现全自动化。
3级:代表有条件的自动驾驶。司机需要时刻监控系统并在关键时刻介入。当然,一些安全功能也会在某些情况下自动介入。
4级:就是高级别的自动驾驶了,不过它无法覆盖所有的驾驶情况(如恶劣气候),且受到车辆操作设计的限制。不过,司机无需继续监控路况了。
5级:自动驾驶的终极状态,车辆能应对任何状况,司机们宣告彻底失业。

自动驾驶等级的演进离不开硬件升级、算法的持续迭代开发,需要路采车辆上的传感器采集海量的路测数据,并基于处理后的数据进行反复的AI训练和仿真,让汽车能智能地识别和处理各种路况和障碍物,从而实现自动驾驶。当前,主流的自动驾驶环境感知技术路线包括视觉主导和激光雷达主导两种方案:
以特斯拉为代表的「摄像头 + 毫米波雷达 +超声波雷达」多传感器融合,以Autopilot 2.0为例,其硬件由8个摄像头、1个毫米波雷达和12个超声波雷达组成,但摄像头受环境光照影响较大,目标检测较不可靠,优势是成本相对较低。
以 Google Waymo 为代表的「低成本激光雷达 + 毫米波雷达 + 超声波传感器 + 摄像头」多传感融合,激光雷达是主动视觉,目标检察较为可靠,但缺少颜色和纹理信息且成本较高。
不同的技术路线及自动驾驶L1-L5不同阶段,每辆车安装的雷达、摄像头、传感器数量和精度要求存在差异,产生的数据量也不同。当前大多车企及供应商还处于L2-L3阶段,每辆车每天产生的数据量约几TB-几十TB。
车载传感器数据量
而随着汽车自动化程度越高,车辆训练所产生的数据量也会越大。当前几个主要等级车辆研发所需要的测试里程和数据量如下:
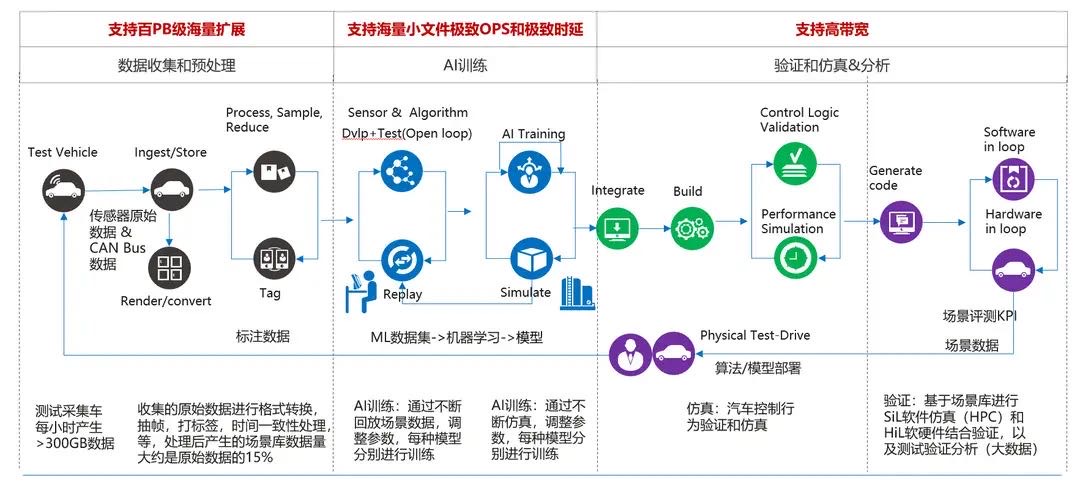
自动驾驶路测数据量
基于AI开展数据挖掘,实现汽车智能
数据和AI是自动驾驶汽车的核心,越长的测试里程、越多的数据量、越高效的训练和仿真手段,自动驾驶汽车的竞争力也越强。自动驾驶研发的每一个阶段,对于数据和存储的需求也不尽相同,如下是简化的数据处理流程:
自动驾驶训练和仿真流程
数据收集及导入:通过车载SSD,按照时间片(分钟级)对各摄像头、传感器采集的数据进行打包存储,每车每天约产生2TB-64TB数据。车载SSD数据通过快递邮寄回数据中心并导入到存储系统,一般需要在8小时内导入完成,对存储系统带宽有很高的要求。
数据预处理:采用Hadoop等并行框架将多辆车路采数据进行分离、格式转化、抽帧、时间一致性处理,最后做初步标记(车号、采集时间、天气等)。
AI训练:通过不断回放场景数据,调整参数,进行反复的深度学习和迭代训练,得出最优的决策模型。由于训练主要针对小图片,训练的数据量大、次数多,要求存储系统能够提供极致的OPS和时延。
仿真验证:通过HPC平台,对AI训练的结果进行SiL(Software in Loop)和HiL(Hardware in Loop)仿真,仿真结果可以通过Hadoop进一步分析,最终将新的算法/模型部署回测试车辆。
OceanStor分布式存储,让海量数据分析更高效
自动驾驶带来的海量数据存储及高效分析需求,给底层的存储系统带来了巨大的挑战。传统的存储系统在扩展性、性能、数据流转效率上均存在较大的差距,基于OceanStor分布式存储的智能数据湖方案,成为越来越多客户的选择:
EB级扩展:自动驾驶每车每天产生几十TB数据,几十辆测试车,一年产生的数据量就有上百PB。OceanStor分布式存储可提供EB级扩展能力,支持冷热数据分级,让路采数据可以以更优的成本长期保存,挖掘出更多的价值。
协议互通:自动驾驶的数据处理,涉及到文件接口的数据导入、AI训练和仿真,又涉及到HDFS接口的Hadoop分析,未来5G商用了还可能涉及对象接口的数据回传。OceanStor分布式存储可提供文件/对象/HDFS协议互通能力,数据无需拷贝即可在流程的不同环节快速使用,很大程度上提升数据的分析效率。
高带宽&高OPS:自动驾驶处理流程的不同阶段,既有高带宽的性能要求,又有高OPS、低时延的性能要求。OceanStor分布式存储通过架构创新和自研硬件,一套存储即可同时满足高带宽&高OPS需求,避免不同流程阶段使用不同架构的存储而产生的数据拷贝。
自动驾驶的未来应用场景
随着技术的不断进步,自动驾驶等级将逐步提升,数据与汽车的完美结合,将散发的更大的魅力,影响更多的行业和场景,OceanStor分布式存储也致力于和自动驾驶技术一道,为各行各业打造坚实的海量、多样性数据底座。
 2人点赞
2人点赞
评论